Proponents of self-describing storage cite this ability to uniquely tailor the information stored to each item as one of the style's big benefits. Adding "one-off" properties to items, they claim, is a natural need of information storage.
But is it?
Well, here's a short analysis I did the other morning that provides some evidence to help answer that question. I took about 1,800 datasets that I scraped from visualizations on the web and looked that property coverage for each property in the dataset. Let's define the property coverage for property P as the number of items that have property P divided by the total number of items in the dataset. Property coverage of 1 means every item has the property. Property coverage of 0.5 means half of the items do.
Some of the datasets for these visualizations were authored in JSON, a self describing format. Others were authored using Google Spreadsheets, a schema-based format. If customizing items with one-off properties is truly one of the empirical benefits (not just claimed benefits) of self-describing storage, then we should expect to see more low-coverage properties in the JSON datasets.
And here is the graph with the results:
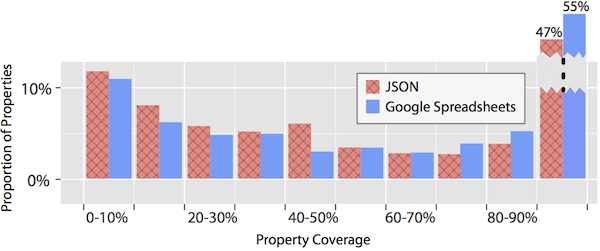
It's nicely split into three general segments: authors who use JSON tend to create more properties with 0-50% coverage. Between 50% and 70% it's a wash. And spreadsheet authors tend to use more properties with between 70% and 100% coverage.
While you can't make any strong claims from this data, it does suggest that one-off (low coverage) properties are actually used in datasets in the wild. And if this chart generalizes, then users of self-describing formats make use of low coverage properties more often than users of schema-based formats, supporting the idea that this is one of the benefits to the approach in practice, as well as theory.