Background tasks are a critical component of web applications. These tasks often perform work that takes too long to place inside the request-response loop of the app server. For example, many of our tasks at Cloudstitch involve synchronizing data between third-party services like Eventbrite and Google Spreadsheets.
The typical background task setup most of us are used to is what you might call the Big Fat Worker Machine Model. Whole computers, maybe EC2 instances, running whatever you want. In this setup, handling a background task is as simple as writing a program that takes and input and saves an output.
 The Big Fat Worker model of background tasks.
The Big Fat Worker model of background tasks.
But with the growing microservice trend, this worker-machine model no works. The web of background tasks on AWS Lambda look more like a swarm of ants each contributing a bit of labor to a piece of meat dropped on the ground. Some are working in parallel. Others show up later to finish the job off. And messaging between workers isn’t always explicit and linear: services like AWS Lambda encourage execution to be triggered implicitly, via S3 and DynamoDB events, rather than explicitly via function calls or queue pushes.
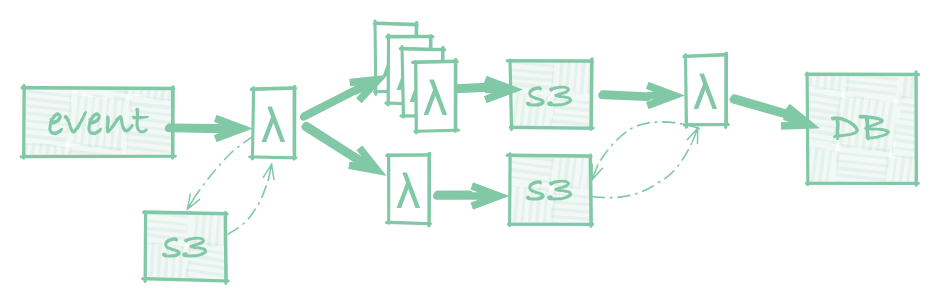 A single background task accomplished with an Ant Swarm of workers.
A single background task accomplished with an Ant Swarm of workers.
Managing state across all the workers in that ant swarm can be a challenge:
- The work is split across many, possibly parallel workers
- Some execution, invocation, and restart control is ceded to the platform
- No global scope exists to monitor the state of the entire ant swarm operation at once
I’ve tried a lot of different approaches to handling this problem while building Cloudstitch, and while I don’t have a silver bullet solution, I have settled on a pattern that seems to be working well enough to share. That approach is to **coordinate background tasks with log-append job records in S3 (or DynamoDB). **What follows is targeted at the AWS ecosystem but easily adaptable to other microservice infrastructures.
Here’s how it works. Each background task stores its state in a a job file. This file is logically one JSON object, but physically a log structure of refinements to some initiating object. Each job-n is an overwriting refinement to job-{n-1}. That means the task is initially represented by a single physical JSON object uploaded to S3. As microservices contribute work to the task, they modify the state of the task by creating new files.
Your job metadata is logically one file, but physically a time-ordered log structure in S3.
This strategy enables easy leveraging of the events S3 can throw to Lambda. **Every time a refinement is appended to the log, it triggers a re-evaluation of the overall job status. **That’s done by a router function which acts as the ant queen, so to speak, to keep an eye on the swarm of ants as they report on their status. When job-n.json is uploaded, the router is triggered, downloads and merges **job-{1:n}.json **into a single state object, and decides what to do next.
The lifecycle ends up looking like a back and forth between S3 events, the router function, and worker functions:
- **Creation. **Uploading an initial job.json file to S3 kicks off the router, which begins issuing lambda calls (or pushing log refinements which, passively trigger more work).
- Ant Swarm. Each piece work done finishes with a log append in S3, triggering the router to take a look and possibly request more work. For example, if all 10 of 10 web scraping sub-tasks are complete, the router might decide to initiate the next phase of labor.
- Completion. Eventually, a log append is pushed that results in the logical job file achieving some completion state. In this case the router finishes the job off — notifying callers, saving to a database, whatever is appropriate.
Overall, I’m pretty pleased with the setup. It’s a bit more work up front to organize a cascade of tasks this way, and there’s admittedly a lot bookkeeping overhead if your sub-tasks are small, but it scales wonderfully.
Here’s an NPM module called Pile On I’ve created to help manage JSON objects and arrays of this access pattern. This just helps with the file management described above. For example, you can:
// Create a new Job File
Pileon.create(S3Bucket, 'job.json', {state: 'running', x: 1});
// Append/overwrite the Job File
Pileon.append(S3Bucket, 'job.json', {state: 'finished', y: 3});
// Fetch a promise for the merged file
// {state: finished, x: 1, y:3}
var promise = Pileon.readObject(S3Bucket, 'job.json');
I’ve got a few more helper libraries I’ll be packaging down the road to handle the execution management of jobs managed this way. In the meantime I’d love your thoughts. It’s a wild world of experimentation out there in microservice land and I know there are a lot differing strategies.