Machine learning is at the cusp between research and engineering. On the one hand, many ML techniques have become simple off-the-shelf libraries. On the other hand, the state-of-the-art still can’t solve many important problems.
Product management in this environment is thrilling: how do you create products that solve problems residing on the other side of the wall of impossibility? How do you bend the wall so you can get around it?
I’m using “impossible” as a relative term: it could be the limits of the field itself. Or of your knowledge, or of your time or budget.
In all cases, it’s the same answer: to solve an impossible problem, redefine it until it becomes easy.
Observation: Your problem statement probably assumes too much
Product opportunities, as we encounter them in industry, are often handed to us like a chess board waiting for a next move:
“Hey! I’ve got a bunch of images of scanned documents… could you build an app that detects if they’ve been signed?”
It’s tempting to start from that chess board. To start with a customer’s description of some defined state (images of scanned documents), a defined set of rules (things you can do to images), and the customer’s perception of the goal (signature detection).
But often times the best way to solve a hard problem is to ignore the details of its formulation while keeping the essence. What if that’s not what you really had, and not what you really wanted? What if we could translate your chessboard into a checkerboard and solve an analogous problem in an easier space?
Example: “Free like a bird” with Laplace Transformations
My differential equations professor was an old Italian man who wore a red knit sweater every day for half the semester and then suddenly changed it to green without warning. I’ll never forget the day he taught the Laplace Transform.
The Laplace Transform is a “function of functions”: it takes a function as input and produces a function as output. It’s a mathematical wormhole, a way to teleport yourself into a universe that behaves with a different set of rules. Things impossible to solve on one side become trivial on the other side, and vice versa. The original video game cheat code.
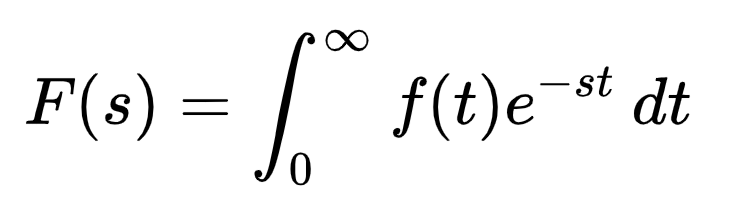
By the end of his lecture he had whipped himself into a frenzy.
“Ladies and Gentleman!” he said in his thick accent, “you have just witnessed the solution to an unsolvable problem. The function f, which was trapped in the cage of t, is now free to fly like a bird in s. We have solved the unsolvable by transporting it to a better universe in which things are easy.”
I sat in the empty room after class, staring at the chalkboard for twenty minutes. I didn’t even like differential equations, but it was one of the most impactful hours of my life.
I had been modeling the world, and problem solving, like a player inside the game. But here was an example of cheating, of playing god. Redefining the rules of the game itself so that the soccer ball always went into the net.
Application: Signature detection at Instabase
Here’s an example from our work at Instabase. Let’s return to signature detection. Imagine a customer has a thousands of cell phone photos of tax returns and wants to know how difficult it would be to detect whether they are signed.
Your job, as a part of the product team, is to figure out if we could make a Signature Detection app that works at production scale and on arbitrary datasets.
-
The Chess Solution (inadvisable)
Immediately jump into machine-learning mode and begin playing with image processing algorithms
-
The Translate-to-Checkers Solution (do this instead)
Go on a walk and think about how you could rewrite the rules of the problem
Let’s look at the chess-style thought process:
The customer has a folder of images. That sounds pretty hard. If you do a Fourier transform, handwriting has a very different frequency than printed text, but how would you be sure you could separate the two? What if it’s photocopier noise, or margin notes, or just beautiful handwriting that looks like printed text to the computer’s eye? Or we could just go full deep-learning, but what would our training dataset need to be for robustness across document types? Would our app require GPUs to run on-premise? ...and so on...
Now let’s look at the checkers-translation thought process:
What if we could redefine what our inputs were. Instead of images, we just assume access to other information that we know is easy to produce. Consider these side-channels of information below, given a single input image (at left):

-
Input 1: Original document image (raw input)
Pixels are still useful! Don’t throw out the original input images the customer gave you.
-
Input 2: Document text (via OCR)
What if we had the text of the document, too? That might be useful: it would let us identify regions of the document based on what it said.
-
Input 3: Linkage between image and text (via OCR metadata)
Could we let the customer search for the text that indicates the signature block, translate that into image coordinates, and then grab the region of the image that occurs to its right?
Let’s assume access to all of these inputs. We’ve taken our chess board (signature detection in an image) and rewritten the rules so that now we can easily query into the input and ask for the region of the image that corresponds exactly to the signature block.
Neat: this redefined input lets us redefine the output we’re looking for as well. Before, we needed to find whether the document was signed. Now, we only need to determine if a cropped, white image contains pen marks. In other words, count the dark pixels.
Now, you don’t have to do it this way. There are always many ways to solve a problem, and the point here isn’t the pros or cons of any one way. The point is that you can often sneak around a hard problem by taking a moment to redefine it until it more closely resembles an easy problem.
Obvious is the the sign of success
You know when you’ve successfully redefined the rules of a game because the solution becomes so easy it’s almost embarrassing to reveal. How does Instabase do signature detection? We count the number of black pixels in a box.
The real trick is realizing that you just needed to find the box.