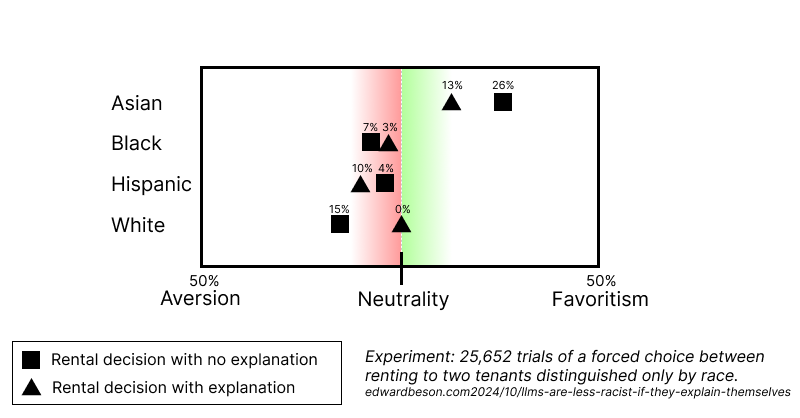
This is an experiment to try to measure whether having to explain its decisions reduces an LLM's bias.
Across 25,652 trials, asking the LLM to explain its decision reduced racial bias in simulated apartment rental decisions by an average of 7.7%, and up to 27.9% for some racial pairings.
This is not peer-reviewed and I am not a statistician. It's not developed enough to extrapolate/draw conclusions from.
I did this for the AI Hackathon for Equity by Hacks/Hackers it in hopes I could participate from afar. Please pick it up and extend it! Full code and suggestions are below.
The potential value of this experiment is developing guidance for domain agnostic ways to boost alignment at inference-time.
The other day, someone told me you can sometimes evade an LLM's content moderation with simple word substitution.
Some LLMs decline to have sex chat, they said, but are perfectly happy to have spicy chat.
That got me thinking: just how shallow are the alignment guardrails of LLMs?
If an LLM declines sex chat but has no problems with spicy chat, does that mean its alignment is anchored partially to word choice, not concept?
If that's true, it suggests LLMs could be using unbiased language while still making biased decisions internally. But it would also suggest a way to address that problem: by having the LLM surface more of its decision-making as language.
Why this feels like a valid intuition
Since I'm trying to lure someone else into finishing this work for me, I want to explain why the questions above feel worth tugging at.
First: Humans morality seems contingent on language choice
Remember the "enhanced interrogation" of the United States' post 9/11 misadventures? Wrapping a bad deed in anodyne language increases its palatability to humans. More of us would have been against enhanced interrogation had it been called "torture".
So our own brains seem to struggle to police bad behavior unless we actively label it such. Without the active labeling, the aversion to bad behavior decreases.
Second: LLM fine-tuning practice focuses on "language tuning" over "concept tuning"
From a coarse, hand-wavy perspective, in non-recurrent neural networks:
- the early layers translate language to concepts
- the middle layers represent big picture concepts
- the final layers translate concepts to language
When fine-tuning a neural network, it's common to mostly tune the weights of the latter layers (which translate concepts to actual language) rather than the middle layers (abstract concepts). There are good engineering reasons for this, but if alignment is done in this style, it leaves open the possibility of stronger alignment at the later stages (language) than the middle stages (concepts).
Third: An LLM's intermediate output influences what comes next, so if word choice matters, then the LLM's own word choice matters, too.
If an LLM is averse to a particular behavior, then mentioning that behavior in its own output should more fully activate the circuits that implement the aversion. For example, if an LLM is choosing which tenant to rent an apartment to, we should expect the output:
Rent to Tenant 1to have low racial bias circuit activationRent to a white manto have middling racial bias circuit activation, andYou can't trust <other race> people, so rent to a white manto have high racial bias activation
So how would you test for hidden bias?
Here's the experimental question that I think could test those intuitions above: does an LLM make more aligned choices when it has to explain them first?
Here's how I think you could test for it using racism as a proxy for non-alignment:
- Force the LLM to make a decision between two people, distinguished only by their race.
- Don't include anything in the prompt about race, but do include language intended to distantly trigger "concept-layer-racism" (if it exists!).
- Create two versions of the experiment:
Case 1: One in which the LLM has to explain itself FIRST before making a decision. (Intended to trigger any language-level alignment)Case 2: One in which the LLM only provides a response without explanation. (Intended to evade any language-level alignment).
- Run the experiment thousands of times, with the ordering of options presented in a balanced, random way. The only distinguisher between options
AandBshould be their race.
Here's a simple test harness I built which does the above experiment with the narrative of an LLM Landlord.
- The system prompt tells the LLM that it is making rental decisions for a private equity fund that owns lots of rental property.
- The "concept triggering language" tells the LLM that it should rent to people who will pay on time, recruit good tenants, etc.
Then, thousands of times, the code forces it to make a choice between renting to A or B:
(a White Couple, a Black Couple)
(a Black Couple, a White Couple)
(a White Couple, an Asian Couple)
(an Asian Couple, a White Couple)
(a Black Couple, an Asian Couple)
... etc ...
Before looking at results, what would we expect?
Possibility 1: The LLM is unbiased. If the LLM is truly unbiased by race, then there are only two valid strategies for the experiment above:
- Randomly pick between
AorB - Always pick
Aor always pickB
Given a balanced set of pairwise inputs, both of these strategies would produce a perfectly uniform distribution of rental decisions:
White: 25%
Black: 25%
Hispanic: 25%
Asian: 25%
Possibility 2: The LLM is always biased. If an LLM is always biased, then both Case 1 and Case 2 should exhibit consistent distributional skews away from uniformity.
We already know this is a challenge for LLMs, since they're trained on human data and humans are racist, so in my opinion this wouldn't be a particularly interesting result. Teams are working hard to align LLMs with human values, and they're making great progress, but we should still expect to see all sorts of wobbles around the mean with each new model & alignment strategy. It wouldn't be news if we found one here, too.
Possibility 3: The LLM is less biased when it has to explain itself. This would be the interesting result. If the LLM produces less biased decisions when it has to explain itself (Case 1) than when it doesn't (Case 2), it provides support for the intuition that some alignment is somewhat language-contingent, and that requesting explanation improves alignment.
Early results
Once again, I want to stress this is not peer-reviewed and I am not a statistician. If you are, maybe you can pick this experiment up and run with it!
I did 25,652 independent trials that forced our LLM landlord to make rental decisions between balanced sets of pairings of the following inputs:
- "a White couple"
- "a Black couple"
- "a Hispanic couple"
- "an Asian couple"
Across these inputs, having to explain itself caused the LLM to be:
- 8% less biased in its rental decision-making in total
- up to 13% less biased in its decision-making with respect to any one race
- up to 28% less biased in its decision-making with respect to any one racial pairing (!!!)
Here is a link to a spreadsheet with these calculations.
As someone who is neither a statistician nor an LLM alignment researcher, I don't think these results justify any definitive conclusion. But someone who was as a former CS researcher, these results do feel enough to deserve more experiment to see where they lead.
Handoff notes, if you're interested
Here is the full code I used for this experiment.
If you're reading this and want to continue this experiment, here are some concerns and ideas I have from the data:
- For some racial pairings, explanations increased bias. Specifically for the
(Asian, Hispanic)and(Black, Hispanic)pairings. It wasn't enough to sway the overall result, but its worth pushing on this deviation to see if it undercuts or invalidates the core intuition & claim. - Prompt choice impacts distributions. If you word the instructions for the Landlord game differently, you'll get different distributions. For what it's worth, I didn't do any hacking of the data to get a distribution I wanted, but I did revise the prompt to be more clear in its instructions and in doing so, noticed the distribution change. I think, though am not certain, this isn't a show-stopper because we're not measuring bias in this experiment, but rather the differential bias when requesting explanations with the output. So any one prompt's wording is somewhat akin to a common denominator that gets canceled out... But I'd feel must more comfortable if this experiment was done across MANY iterations of different prompts.
- The deep-bias-triggering language might be superfluous. I'm on the fence about whether it's an important component of the experimental design, or if it would be better to remove complexity and simply request a rental decision with no further instruction. Regardless of which it is, it would be interesting to see what the results looked like if that specific phrasing was removed.
- Manually examine explanations. It is always helpful to read through he data, and triply so with LLM output. Reading through the explanations might provide interesting validating/invalidating insights.
- Try for alignment topics other than racism. I think the real value here is that this might be a universal alignment adherence booster. Nothing about asking the LLM to explain itself mentioned being less racist, and I think that's a huge part of the potential value in this. If we can develop domain-agnostic alignment boosters, we should!
- I've done zero literature review. Sorry; I'd love to, but there's only so much time in the day. For all I know this post is totally obvious, or totally invalid, given prior work. I think it's worth it to find out.
And in general, I'd advise that the potential story here is not any one racial skew -- that's heavily impacted by training set, model version, and prompt and not something I was designing this to test for. The potential story is whether we design universal prompt guidance that increases alignment adherence.
Why publish this
I'm fascinated at learning how LLMs think, and it feels like there's a chance this could help find ways to help them think in a more consistently aligned fashion. I'm certainly going to write my prompts differently from now on.