OpenAI's deep research feature is deceptively simple: you ask a question, you answer some clarifications, you get a report.
But I think it's useful to think through the design to really pin down how that design might relate to other systems.
Here's the flow in full:
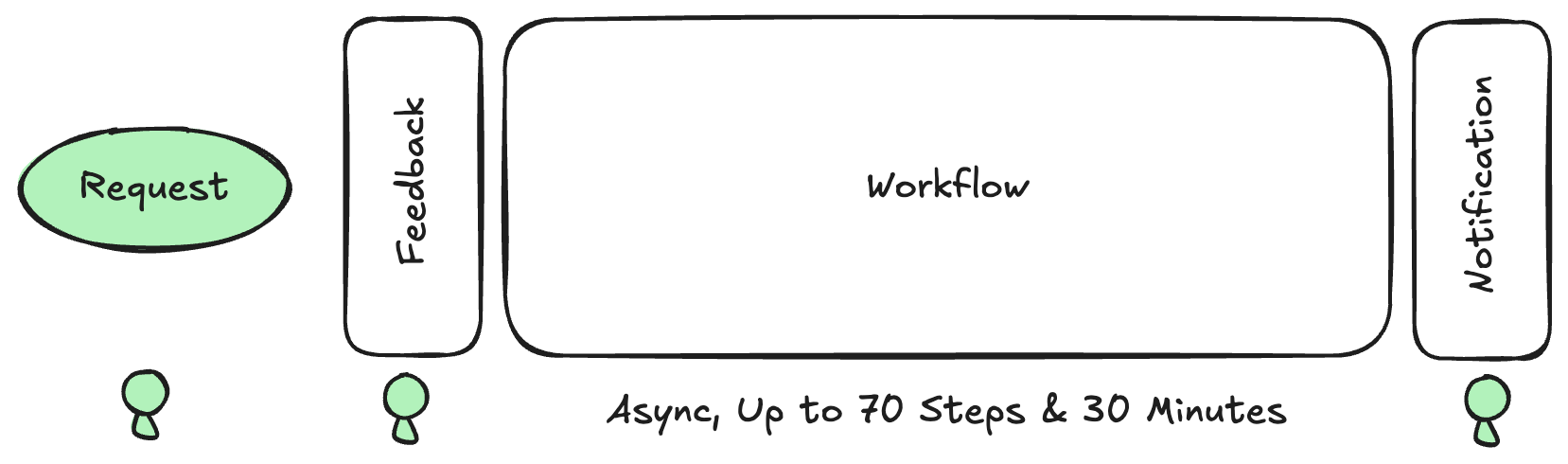
- Always, the user requests a report.
- Usually, the system responds immediately with clarification questions.
- Always, the system then performs the "deep research" work.
- Never, does it return with a follow-up question mid-research (at least in my experience)
- Always, the system notifies the user that the report is done.
Here's what I think we can surmise about this system.
The Workflow - "Fixed.. with Discretion"
The nature of the "deep research" work appears to be an dynamic number of steps in an information-seeking loop, followed by an analysis and writing pass. Somewhere in between a "workflow" and an "agent" depending on how you want to define things. It does only one thing, but it decides by itself when that thing is done.
I've personally seen this loop include over 60 distinct steps and take over 15 minutes.
At a high level, you might imagine that source-gathering process is hand-coded in Python. After all this seems to be a relatively single-purpose workflow.
But after watching how the deep research agent behaves when given an impossible topic to report on (see below), I think the LLM has significant, or complete, control over the process:
- It can identify failed search strategies and then re-route its approach radically.
- It can call arbitrary tools
- It can combine the results of one tool (e.g. a web read about an algorithm on Wikipedia) with non-trivial requests to another tool (running Python)
Error Handling - "Embarassingly Robust"
The clarification step that happens instantly is a form of proactive error management. Given that the workflow which follows can be 50 steps or more, fixing small directional errors up front will save the user from getting back a report that deviates dramatically beyond their intention.
Other than that, the workflow is simple enough that errors are auto-resolved:
- Any web pages that fail to load are ignored, since there are others
- Identity disambiguation and source validation appears to be handled by an LLM within the web scraping loop
Error handling can be so simple because the workflow is always fixed, it's side-effect free (e.g. no database writes or API calls), and no one atomic operation (e.g. web page read) is critical to the overall success.
Much like some processing problems are "embarassingly parallel", deep research is "embarassingly robust".
Experiment: Requesting an Impossible Report
Forcing a system to fail can tell you a lot about how it works.
To that end, I requested a deep research report on the following topic, assuming that no document retrievable will contain the actual string.
kkdjjfi3898fjj3mmj3jr939fu2u7u2hhfmm12fk1o393-34ifj

The LLM which generates clarification questions was rightfully confused at the request when asking for clarification:
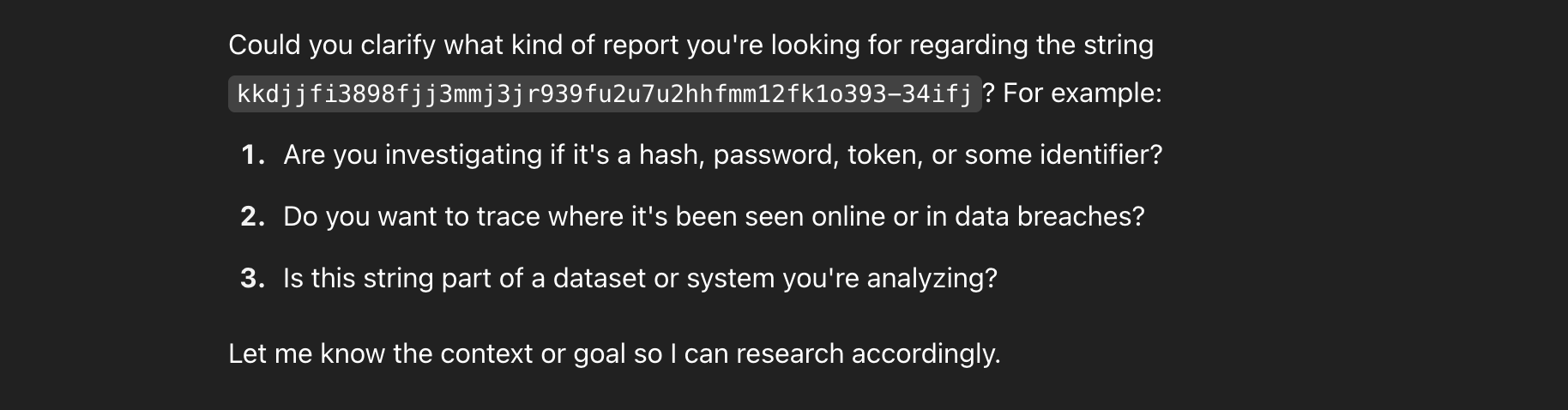
To which I insisted that the report I wanted was on that string itself:

As the research process progressed, the status window showed the workflow pursuing a variaty of options as it concluded that it had come up short on each one.
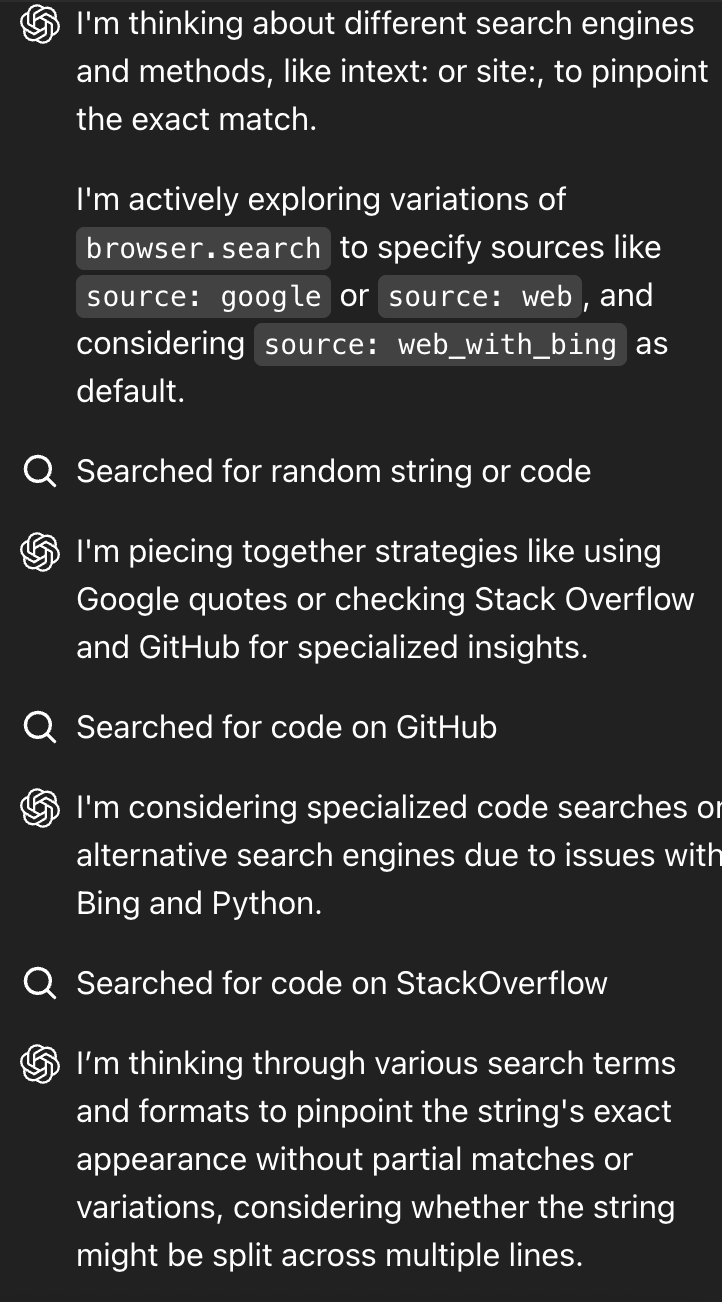
This indicates that the source gathering loop is:
- Aware of the nature and appropriateness of search medium (e.g. Amazon as opposed to Stack Overflow)
- Aware of subtle disambiguation issues (e.g. a substring appearing int he result, but not the whole string)
- Able to actively reject search results rather than blindly accepting all of them.
After hitting Wikipedia, the Deep Research process began learning about different kinds of encoding, which put it in a loop of reading about different encodings and then authoring Python code to run experiments.

While OpenAI occludes the details of this python code, it appeared to be transforming the string using different algorithms to see if it would resolve to a more comprehensible one.
Finally, after 12 minutes, I got back a detailed report providing the case for my string's lack of meaning. The report concluded a breakdown of all attempts to understand its meaning and why they failed.
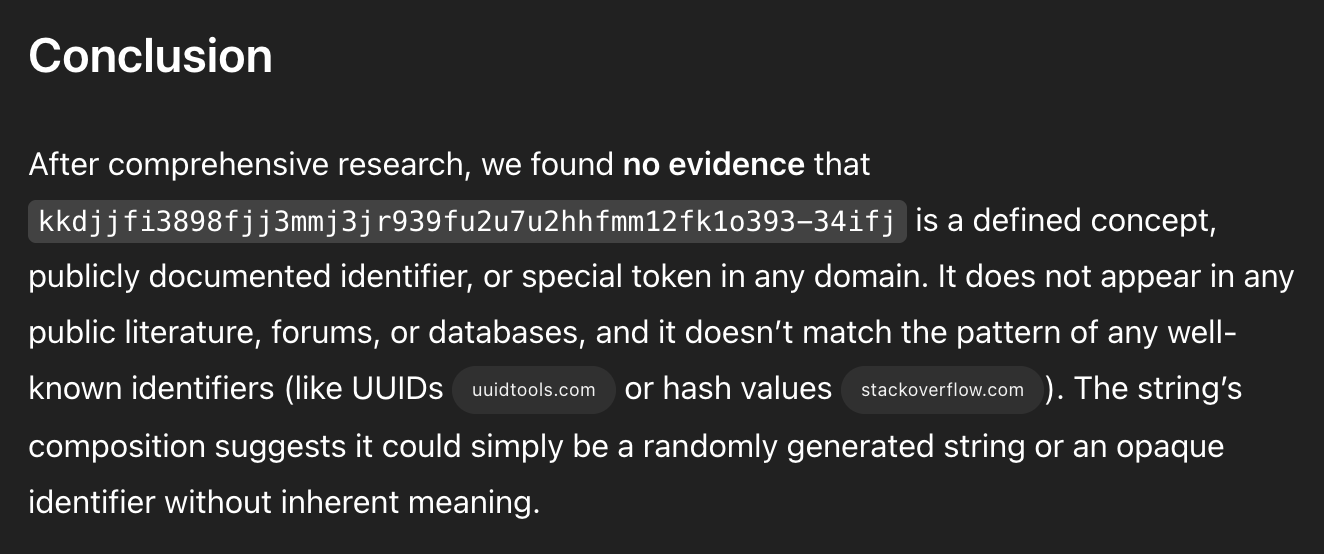
Notably, it did not respond: "I'm sorry, I didn't understand that."
Takeaways for product design
A few high-level takeaways about what could be hoisted from this onto other products:
- "Phone me back when you're done" is now a valid form of consumer software design.
- Instead of error messages, consider a high quality response about the nature of the error.
- Consider separating error mitigation into two parts: synchronous, with the user-in-loop, followed by asynchronous, with just the LLM making calls.